統計分析最常見的假設之一是常態性分布,幾乎所有參數分析都以某種方式要求這種假設。評估常態性的第一步是將變量的繪製成直方圖查看。在直方圖中,X 軸表示變數值,Y 軸表示每個值的有多少參與者。常態分佈的參與者大多在中間,少數在上末端和下末端- 這形成了一個中央”駝峰”與兩個尾巴。
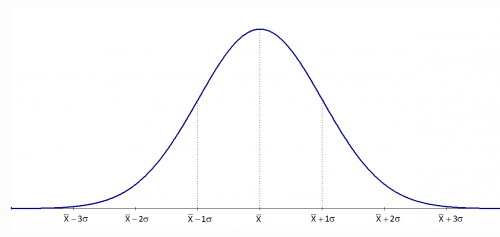
如果數據看起來不像圖 1,則修復此問題的方法是應用轉換。轉換數據是一種通過將數學函數應用於每個數據值來改變分佈的方法。使用數據繪製直方圖,如果看起來像圖 2 中的任何一種圖形,則可以應用給定的轉換方式對應於特定圖形值,並嘗試將數據轉成近似常態分佈。
本頁內的鏈接
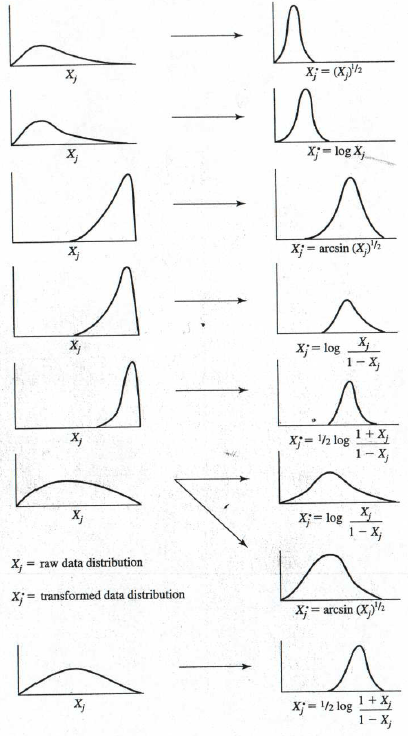
例如,如果您的數據看起來像圖2中第一個圖形,請將該變數的所有值應用平方根(即將變數提高到 ½ 次方)。這很容易在像 Excel 這樣的工作表程式和大多數統計軟體(如 SPSS)中執行。然後,您可以再次重新繪制直方圖,查看新變數的(轉換)分佈與常態分佈做比較。只要樣本量超過30(如果大於50更好),通常不會對非常態數據的效度影響太大。
在轉換之後,數據現在可能大致常態分布,但解釋這些數據可能要困難得多。但是,例如,如果您跑 t 檢定來查檢兩組之間的差異,並且您正在比較的數據已進行轉換,則不能簡單地說兩組的平均值存在差異。現在,您有額外的步驟解釋基於平方根差異的事實。通常,為了讓您的報告對指定讀者有意義,必需要將計算的參數(如中線、上控和下控制限制)轉換回原始的測量單位。
轉換策略
注:大寫字母`X`表示數學中的一個列向量,即 `x_i` 的所有值
-
如果概率圖嚴重向上凸起,則表示X的分佈高度偏向右側:例如,[gssi .csv] 或 [gssi.txt] 的數據用於「轉換為常態」: 試用分佈轉換常態分佈 .
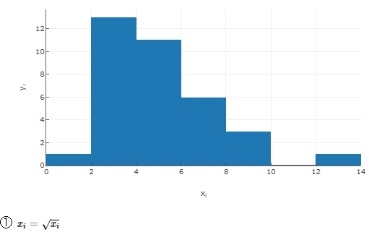
原始數據為整數值( `X^1`,X的1次方)。建議降低X的次方。

-
嘗試`X`開平方根,可以記為`X`的1/2次方 或 `X^0.5` 或`X^½ `。概率圖仍然向上凸起,只是沒有那麼多。
-
嘗試`X`取自然對數 `ln(x)`。概率圖顯示較少向上凸起。

-
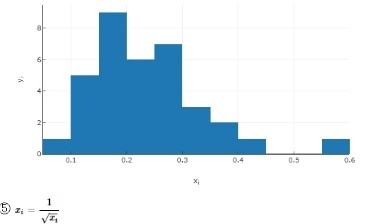
嘗試`X`取倒數開根號`X^-½ `。在平方根上取倒數 1 結果幾乎是一條直線。
-
嘗試`X`取倒數 `X^(-1)`。概率圖看起來令人滿意。

-
嘗試`X^2`平方之後再倒數`X^(-2)`。概率圖看起來直線符合度較差。

`X^(-1)` 將把原始數據轉換為所需的近乎常態的數據。原始手術數據,`x_i` 數據,以表示每個手術部位感染之間的手術次數;`X^(-1)` 是`X`的倒數,因此轉換為“每次手術的手術部位感染次數”。
對於罕見事件(例如住院跌倒)中使用的間隔圖之間的天數:`X` 數據是“每個跌倒的間隔天數”,而倒數是“每天的跌倒次數“。
在處理罕見事件時,轉換尤為重要:i管制圖、t管制圖、g管制圖都對基礎分佈非常敏感;因此,在執行其他檢定(跑統計)之前,最好將其轉換為接近常態分佈。常見範例:
- Weibull分佈 `y^(1/3)` 適合用在g管制圖(不良事件之間的事件)
- 第四根 `y^(1/4)` 適合用在院內感染
峰度 (kurtosis) [3] kurtos {希臘語} 拱形或凸出
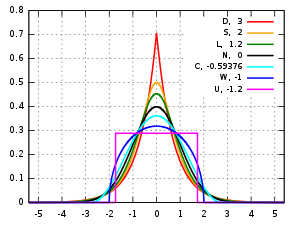
- 中峰(Mesokurtic)
- 峰度通常根據常態分佈進行測量。尾部形狀與標準常態分佈大致相同的分佈被稱為中峰。中峰分佈的峰度既不高也不低,而是被認為是其他兩個分類的基線。
- 瘦高的(Leptokurtic) lepto {希臘語}瘦
- 瘦高峰度是一種峰度大於中峰分佈的分佈。瘦高峰度分佈有時通過細而高的峰來識別。這個分佈的尾巴,不管在右邊和左邊,都是厚和沉重的。最有名的瘦高峰度分佈之一就是 Student's t 分佈。
- 桔梗(Platykurtic) platy {希臘語}寬
- 桔梗峰度分佈是那些具有細長尾巴的分佈。很多時候,它們的峰值低於中峰分佈。
數據分佈和概率分佈並非都是相同的形狀。有些是不對稱的,偏向於左側或右側。其他分佈是雙峰的,有兩個峰值。需要考慮的另一個特徵是極左和極右分佈的尾部形狀。峰度是分佈尾部的厚度或重量的度量。分佈的峰度屬於以下三類分類之一:
峰度過高
這些峰度分類仍然有些主觀和定性。雖然我們偶爾也許能夠看到分佈的尾部比常態分佈更厚,但如果我們沒有常態分佈的圖形可以比較呢?如果我們想說一個分佈比另一個分配更瘦高呢?要回答這類問題,我們不僅需要對峰度進行定性描述,還需要進行定量測量。使用的公式是 μ4/σ4,其中 μ4 是平均值的皮爾遜第四個中心矩,而 sigma 是標準偏差。
現在我們有了計算峰度的方法,我們可以獲得的可以比較的值而不是單看形狀。發現常態分佈的峰度為 3。這個值成為我們的判斷中峰分佈的基礎。峰度大於 3 的分佈是瘦高峰度分佈,峰度小於 3 的分佈是桔梗峰度。由於我們將中峰分佈視為其他分佈的基線,因此我們可以從峰度的標準計算中減去 3。公式 μ4/σ4 - 3 是峰度過高的公式。然後我們可以根據其峰度過高對分佈進行分類:
- 中峰分佈的峰度過高為零。
- 桔梗峰度分佈的峰度過高為負值。
- 瘦高峰度分佈的峰度過高為正值。
偏度(Skewness) [4]
某些數據分佈(如鐘形曲線或常態分佈)是對稱的。這意味著分佈的右側和左側是彼此完美的鏡像。並不是所有數據分佈都是對稱的。數據群不是對稱的被稱為不對稱的。衡量分佈的不對稱程度度量稱為偏度。
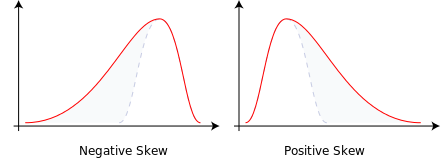
- 右偏
- 數據偏右有一條向右延伸的長尾巴。另一種談論方式,右偏的數據群的另一種說法是說是正(向)偏(斜)。對於向右傾斜的數據集:
• 總是:平均值大於眾數
• 總是:中位數大於眾數
• 大部分:平均值大於中位數 - 左偏
- 當我們處理左偏的數據時,情況會自行逆轉。數據左偏的有一條向左延伸的長尾巴。左偏的數據群的另一種說法是說是負(向)偏(斜)。對於向左傾斜的數據集:
• 總是:平均值小於眾數
• 總是:中位數小於眾數
• 大部分:平均值大於中位數
偏度測量
先查找是一回事,看兩組數據群並確定一組數據較對稱,而另一組數據不對稱。接著另一回事是,看兩組數據,不對稱的一組比另一組更偏斜。僅僅通過肉眼檢視分布圖來確定哪個偏度更高,可能非常主觀。這就是為什麼有多種方法可以數值計算偏度。
偏度的一種度量,稱為 Pearson 的第一個偏度係數,是用眾數中減去平均值,然後將此差值除以數據的標準差。劃分差值的原因是,我們有一個無維度的數量。這解釋了為什麼偏向右側的數據具有正偏度。 如果數據群偏向右側,則平均值大於眾數,因此從平均值中減去眾數會得到正值。類似的論點解釋了為什麼偏向左側的數據具有負偏度。
Pearson 的第二個偏度係數也用於測量數據群的不對稱性。對於這個量,我們用中位數減去眾數,將該數乘以 3,然後除以標準差。
Jarque-Bera 檢定 [5]
Jarque-Bera檢定是對常態性的檢驗。常態性是許多統計檢定的假設之一,如 t 檢定或 F 檢定:Jarque-Bera檢定通常在這些母數檢定之前進行,以確認常態性。它通常用於大數據群。具體來說,該檢定與數據的偏度和峰度相匹配,以查看數據是否與常態分佈相匹配。
常態分佈的偏度為零(即隨平均值完全對稱)和峰度為 3。
J-B檢定的虛無假設是偏度為零且峰度過高為零的聯合假設。當 p 值> 0.05 時,人們通常會說數據與偏度和超峰度為零一致。
J-B檢定統計公式(通常縮寫為JB 檢定統計)如下:
舉例 [11]
將以下數字填入Excel 欄B2:B16
1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, 6, 7, 8
| 參數 | 結果 | 儲存格 | Excel 公式 |
|---|---|---|---|
| 個數 | 15 | B18 | =COUNT($B$2:$B$16) |
| 偏度 | 1.499564 | B19 | =SKEW($B$2:$B$16) |
| 峰度 | 1.072465 | B20 | =KURT($B$2:$B$16) |
| JB 檢定 | 7.943849 | B21 | =(B18/6)*(B19^2)+((B20-3)^2)/4) |
| p-值 | 0.018837 | B22 | =CHISQ.DIST.RT(B21,2) |
解釋:一般來說, 太大的JB 值表示錯誤即不是常態分佈。JB值為 0 表示數據常態分佈。p 值可以使用具有兩度自由度的 Excel 函數 [10] 計算:本範例中原始數據的 p 值為 (0.018837) 小於 0.05;同時另一個檢定法 大(指JB >1.0)JB 值(7.943849)測試中意味著您可以拒絕虛無假設(因為7.943849 > 1.0)即數據不是常態分佈的。
計萛 [8]
計算偏度和峰度的使用以下公式:
偏度為 `beta_3` 峰度為 `beta_4` (有時峰度是指”峰度過高”,它是β4−3)
| 圖形 | 偏度 | 峰度 | JB 檢定 | p-值 | >0.05 |
|---|---|---|---|---|---|
| 原始數據 | -0.000 | 1.798 | 2.107 | 0.349 | Y2 |
| ① | 1.395 | 5.502 | 20.480 | 極少數 | - |
| ② | 0.809 | 3.816 | 4.788 | 0.091 | Y4 |
| ③ | 0.738 | 3.669 | 3.827 | 0.147 | Y3 |
| ④ | 0.108 | 2.985 | 0.068 | 0.966 | Y1 |
| ⑤ | 1.199 | 5.048 | 14.500 | 0.0007 | - |
| ⑥ | 2.592 | 11.099 | 134.839 | 極少數 | - |
| ⑦ | 4.528 | 23.933 | 758.596 | 極少數 | - |
| ⑧ | 2.796 | 13.013 | 191.817 | 極少數 | - |
解釋:使用 p 值 >0.05 作為決策點 (5%),右列顯示四列(原始數據和三個轉換後資料)超過了此閾值(上標表示該轉換在實現常態分佈方面的強度;即即,Y1 > Y2 > Y3 > Y4)。
要得到同樣的結果只使用JB檢定分數(那些最接近於零);然而,這些結果中只有一個小於 1(最接近於零)。由於常態分佈的 JB 檢定為零,Y1 `ln(x_i)` 似乎是這組數據的最佳轉換選擇。
關鍵文獻
- Hart MK, Hart RF. Statistical process control for health care. 2000 www.amazon.com
- Transforming Data for Normality www.statisticssolutions.com
- Taylor C. How to classify the kurtosis of distributions 2020-08-28 www.thoughtco.com
- Taylor C. What is skewness in statistics? 2020-08-25 www.thoughtco.com
- Kurtosis en.wikipedia.org
- Skewness en.wikipedia.org
- McNeese B. Normal probability plots www.spcforexcel.com
- whuber (Moderator) How to efficiently calculate Kurtosis and Skewness of data having value with repetitions? stats.stackexchange.com
-
Glen S.
Jarque-Bera Test
From StatisticsHowTo.com: Elementary Statistics for the rest of us! www.statisticshowto.com - CHISQ.DIST.RT Function: Calculates the right-tailed probability of a chi-square distribution corporatefinanceinstitute.com
- Bobbitt Z. How to Transform Data in Excel (Log, Square Root, Cube Root) www.statology.org